
“Statistics is like a high-caliber weapon: helpful when used correctly and potentially disastrous in the wrong hands” -Charles Wheelan

“It’s easy to lie with statistics, but it’s hard to tell the truth without them” – Andrejs Dunkels
Ketertarikan saya terhadap buku ini diawali dengan melihat:

Kata ‘advanced’ dan nama-nama software yang belum pernah saya gunakan, sedikit-banyak membuat saya sakit perut. Tugas akhir S1 saya memang menggunakan statistik, tapi bisa dibilang sangat basic, dan hanya menggunakan SPSS. Alhasil, saya merasa perlu pemanasan untuk bisa mengenal statistik lebih dalam, salah satunya saya pikir dengan membaca buku ini. Terlebih setelah saya baca komentar dari author buku Fault Lines: How Hidden Fractures Still Threaten the World Economy, “Are you one of those who dread statistics? fear no more. Charles Wheelan explains the intuition behind the various statistical concepts we use in an easy and accessible way”
Overall, buku ini menarik, apalagi bagi saya yang tidak terlalu suka teori. Banyak contoh real life dan applicable. Supaya saya sendiri tidak lupa isi ke-13 bab dari bukunya, saya coba merangkumnya di sini (sebisa dan sepaham saya).
Ch. 1 What’s the Point? (p.1-14)
Di halaman 14, secara garis besar statistik memiliki fungsi untuk:
- Summarize huge quantities of data
- Improve decision-making
- Answer important social questions
- Recognize patterns
- Catch cheaters and prosecute criminals
- Evaluate the effectiveness of policies, programs, drugs, medical procedures, etc.
- Catch the scoundrels who use unethical methods for improper nefarious purposes
Ada bagian cukup menarik saat membahas statistical detective work, yang mungkin dapat menjadi alarm ketika ke depannya kita akan menggunakan statistik sebagai alat penelitian “statistic is not to do math, or to dazzle friends and colleagues with advance statistical techniques. The point is to learn things that inform our lives” (p.13). Kalau saya pribadi justru makin senang kalau set data yang saya punya dapat diuji dengan metode yang sederhana/bahkan bisa dites secara manual. Alih-alih menggunakan uji korelasi yang rumit yang memberi peluang saya untuk mengotak-atik data, saya lebih baik menyesuaikan dari awal variabel, skala pengukuran, dll di awal.
Statistik tidak hanya digunakan dalam penelitian, dalam pertandingan olahraga pun kerap kali kita temukan. Data tersebut jelas digunakan untuk melihat performa tim dan menganalisa apa yang salah dengan timnya. Pemain dapat mengetahui bagaimana seharusnya ia bermain (mengurangi gerakan atau tindakan yang tidak efektif). Tapi ya sekali lagi, statistik bukanlah dewa. Tidak jarang sebuah klub bola memenangkan pertandingan walaupun ia kalah secara statistik.

Ch. 2 Descriptive Statistics (p.15-35)
Statistika Deskriptif adalah cara untuk mengatur, merepresentasikan, dan mendeskripsikan kumpulan data menggunakan tabel, grafik, dan berbagai parameter numerik lainnya. Berikut beberapa istilah dalam Statistika Deskriptif:
- Mean – Nilai rata-rata dari data numerik/angka.
- Median – Nilai tengah yang membagi data terurut menjadi 2 bagian sama besar.
- Standard Deviation – ukuran penyimpangan dari distribusi normal. Nilainya akan mempengaruhi bentuk kurva distribusi normal. Jika nilainya kecil, maka kurva distribusi normal akan berbentuk tinggi dan ramping, sedangkan jika nilai rendah maka kurva distribusi normal akan berbentuk sebaliknya.
- Variance – Nilai yang menggambarkan seberapa bervariasi/beragamnya suatu data bertipe numerik/angka.
- Modus – Nilai yang paling sering muncul dari data.
- Correlation – Nilai yang menggambarkan keeratan hubungan antara dua variabel numerik. Belum tentu menggambarkan hubungan sebab akibat.
- Outlier – data yang berada di luar pola data secara umum, biasanya membuat distorsi pada data (pencilan)
- Kuartil, yg masih satu konsep dengan persentil. Kuartil membagi data menjadi kuarter/empat bagian. Ex: Jika si A berada di kuartil ke-3 (kuartil atas) dari peserta tes, maka 75% orang berkinerja lebih buruk dari si A pada tes ini, dan si A berada di 25% teratas
Dalam bab ini Prof. Charles memberi berbagai analogi kasus untuk memahami istilah-istilah di atas. Contohnya bagaimana dengan kondisi ekonomi masyarakat kelas menengah Amerika? dan siapakah pemain baseball terbaik sepanjang masa? Yang menarik dari penjabarannya adalah: kita harus hati-hati dalam menarik kesimpulan dari kumpulan data. Statistik mengandung unsur subyektif, karena memerlukan banyak pertimbangan manusia agar dapat digunakan dengan benar.
Kita dapat menemukan nilai median dalam data, tetapi sebenarnya rata-rata lah yang mungkin merupakan penggambaran fakta yang lebih baik dalam kondisi nyatanya. Atau juga sebaliknya, kita dapat menemukan nilai rata-rata dalam kumpulan data, tetapi sebenarnya median mungkin merupakan penggambaran fakta yang lebih baik dalam kenyataan (ex: penghasilan rata-rata orang-orang di bar lokal, tetapi kemudian Bill Gates masuk). Dengan demikian, penilaian manusia berarti segalanya dalam statistik
Ch. 3 Deceptive Statistics (p.36-56)
Penilaian dan integritas ternyata sangat penting. Pengetahuan statistik yang terperinci tidak menghalangi perbuatan salah seperti halnya pengetahuan terperinci tentang hukum mencegah perilaku kriminal. Justru orang yang ahli dapat lebih mudah mengatur set data.
Ch. 4 Correlation (p.57-67)
Dua variabel yang diuji dengan metode statistik akan menunjukkan kekuatan korelasi. Hal ini daat dilihat dari nilai koefisien korelasi. Koefisien korelasi mengukur hubungan antara dua variabel (mulai dari -1 hingga +1). Koefisien korelasi -1 berarti ada korelasi negatif sempurna antara 2 variabel. Koefisien korelasi +1 berarti ada korelasi positif sempurna antara 2 variabel. Koefisien korelasi 0 berarti tidak ada korelasi sama sekali antara 2 variabel.
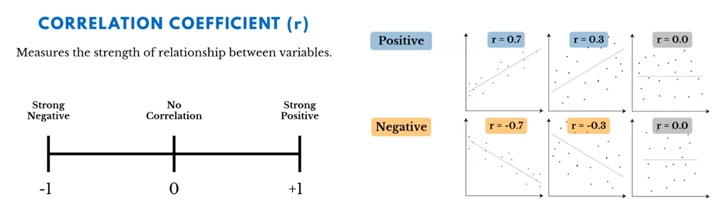
Dalam kehidupan sehari-hari, korelasi ini dapat menjadi basis dalam penyusunan algortima. Misalnya bagaimana netflix merekomendasikan film untuk tiap penontonnya. Netflix will recommend films that like-minded customers have rated highly but that they have not yet seen.
Ch. 5 Basic Probability (p.68-94)
Semakin besar subjek uji, rata-rata hasil akan semakin dekat dan mendekati nilai yang diharapkan. Beginilah cara perusahaan asuransi, kasino, dan perusahaan lotere menghasilkan uang. Memang akan ada pembayaran, tetapi dalam jangka panjang uang yang masuk akan lebih banyak daripada yang keluar. Asuransi sebetulnya tidak akan menghemat uang kita dalam jangka panjang. Apa yang akan dilakukannya adalah mencegah kerugian yang besar.
“In other words, printer companies are selling you something (insurance) that they wouldn’t want to buy themselves (you are being scammed). You should always insure yourself against any adverse possibility that you cannot comfortably afford to withstand. You should skip buying insurance on everything else”
Kemudian dibahas tentang Monty Hall Problem dari game show Amerika (Let’s Make a Deal!) yang diadaptasi juga di Indonesia dengan nama Super Deal 2 Milyar. Marylin vos Savant menyarakan player untuk “switch” instead of stick di pilihan pertama karena probabilitas memenangkan mobil akan lebih besar. Gampangnya: ada 3 pintu, 2 dengan zonk, dan 1 hadiah. Pilih satu pintu dan peluang mendapatkan zonk adalah 2/3. Artinya, player akan lebih berpeluang mendapat zonk drpd hadiah. Jadi switching gives you better chance to get the prize.
Ch. 6 Problems with Probability (p.95-109)
“Statistics cannot be any smarter than the people who use them, and in some cases, they can make smart people do dumb things. Probability doesn’t make mistakes; people using probability make mistakes.” Berikut adalah most common probability errors, misunderstandings, and ethical dilemmas
- Assuming events are independent when they are not
Kejadian peristiwa A tidak dipengaruhi/tidak mempengaruhi probabilitas terjadinya peristiwa lainnya. Contoh: mengocok dadu sebanyak 6x tidak akan mempengaruhi peluang keluarnya gambar pada tos-tos-an koin, dan begitu pun sebaliknya

- Not understanding when events are independent,
–Gambler’s Fallacy: sesuatu yang terjadi secara berturut-turut dinilai menyimpang dari kebiasaan, maka kemungkinkan untuk hal itu terjadi lagi pada masa berikutnya akan lebih kecil dari probabilitas yang sebenarnya.
–Hot Hand Fallacy: Keyakinan irasional bahwa seseorang yang berhasil di waktu X, memiliki peluang lebih besar untuk sukses di waktu-waktu selanjutnya. Misal: seseorang beranggapan bahwa peluang untuk tidak tertular Covid-19 semakin membesar setiap harinya. Atau seseorang yg bermain judi dan mendapat untung di bulan April, akan yakin untuk untung trading saham lagi di bulan-bulan selanjutnya tanpa didasari strategi yang rasional.

- Clusters happen
Kejadian yang jarang terjadi kemungkinan terjadi jika diberi waktu dan pengulangan yang cukup. - The prosecutor’s fallacy
“The chances of finding a coincidental one in a million match are relatively high if you run the sample through a database with samples from a million people”. Sebagai contoh: seorang ibu kehilangan 2 anak bayinya ec Sudden Infant Death Syndrome (SIDS) dalam 2 tahun berturut-turut. Padahal, insiden SIDS adalah 1/8500, sehingga probabilitas insiden dua kejadian SIDS dalam keluarga yang sama adalah (1/8500)2 atau 1/73000000. Oleh krn itu, penting melihat faktor lain yang mungkin menjadi faktor risiko SIDS, misalnya genetik, demografi keluarga, usia ibu saat hamil, perokok pasif/tidak, riwayat menerima kekerasan, dll. So, a probability is rarely the whole story. - Regression to the mean
Even if events far above or below the mean take place, they are likely to regress towards the mean given enough repeated samples (law of large numbers). For easier understanding, just watch it:
- Statistical discrimination
Misalnya pada pemberian premi asuransi mobil (auto insurance) yang berbeda untuk laki-laki dan perempuan di Uni Eropa (diskriminasi jenis kelamin; anggapannya: lakki-laki memiliki risiko tabrakan lebih tinggi dari perempuan, padahal nyatanya women crash more than many men) dan perempuan membayar lebih tinggi dari laki-laki untuk annuities (premi asuransi umum yg dibayar tiap bulan) dgn anggapan bahwa perempuan memiliki angka harapan hidup yang lebih tinggi, padahal pada kenyataannya tidak selalu begitu, seringkali men live longer than many women. Hal demikian terjadi krn perusahaan asuransi care only about what happens on average. Jadi, keliru untuk mendiskriminasikan seseorang berdasarkan faktor-faktor yang tidak relevan, dengan menggunakan statistik.
Ch. 7 The Importance of Data (p.110-126)
“Garbage in, garbage out”
- Selection bias
Ketika individu, kelompok atau data dipilih secara tidak tepat untuk analisis, tanpa pengacakan/randomisasi yang tepat, hal ini akan menyebabkan sampel yang diperoleh tidak mewakili populasi yang luas. Misal bertanya ttg pilihan pemilu di TPS dekat tempat tinggal Megawati, maka kemungkinan besar pemilih akan memilih PDI-P, sampel tidak mewakili golongan lain. - Publication bias
Karena big trials are getting published and the small negative trials are not. Walaupun sebenarnya dari small trials tersebut dapat membuat hasil big trials berubah secara signifikan. Misalnya dalam studi efektivitas glukosamin untuk mengatasi OA dibandingkan dengan plasebo, ada beberapa institusi (baik akademik dan industri) yang conduct riset ini, namun hasil uji yang skalanya lebih kecil malah sehingga tidak mempengaruhi funnel plot. - Recall bias
“Systematic error that occurs when participants do not remember previous events or experiences accurately or omit details”. Contohnya penelitian yang dilakukan untuk mencari asosiasi antara pengaruh berada di ruangan yang sama dengan orang yang terinfeksi covid-19, dengan kejadian penularan covid-19 itu sendiri. Pengambilan data dilakukan setelah subjek/orang-orang meniggalkan ruangantersebut. Peneliti bertanya “apakah di dalam ruangan tadi Anda mendengar suara batuk/bersin?” lalu subjek tsb otomatis akan memberi jawaban dengan mengingat-ngingat kejadian di dalam ruangan. Hal ini akan menimbulkan bias, karena jawaban tsb pastilah hanya perkiraan si subjek.

- Survivorship bias
Mudahnya, subjek penelitian yang digunakan adalah mereka yang memiliki tren positif dalam topik yang diteliti, dengan mengenyampingkan subjek-subjek lain yang gagal. - Healthy user bias
“People who take vitamins regularly are likely to be healthy — because they are the kind of people who take vitamins regularly”. Jadi harus dipastikan sebisa mungkin subjek-subjek yang diikutkan dalam penelitian medis memiliki kondisi awal yang sama, at the same health state. Berbeda degan uji subklinis dan tingkat di bawahnya, peneliti bisa melakukan treatment habituasi terlebih dahulu untuk hewan ujinya sehingga cenderung terhindar dari bias ini.
Ch. 8 The Central Limit (p.127-142)
Semakin besar sampel, maka semakin baik gambarannya terhadap populasi. Sampel biasanya tidak akan menyimpang tajam dari populasi yang mendasarinya sehingga bentuk distribusi sampling dari rata-rata sampel cenderung mendekati distribusi normal.

Ch. 9 Inference (p.143-168)
Prof. Charles menceritakan pengalamannya, dulu ia tidak begitu menyukai statistik. Pada saat midterm, nilainya biasa-biasa saja, tapi kemudian di final test, nilainya sangat baik sehingga ia dipanggil ke ruangan dosennya. Prof. Charles dicurigai melakukan kecurangan. Padahal, hal ini tidak akan terjadi jika kasus sebaliknya terjadi. Karena P(A|B) ≠ P(B|A)
Seperti yang kita ketahui, bahwa untuk menarik keputusan dalam penelitian, diperlukan 4 langkah, yakni: formulate a hypothesis fid the right test, execute, make a decision. Hipotesis sendiri adalah “an idea that can be tested”. Ada dua jenis hipotesis: null (H0) dan alternative (HA atau H1). Hipotesis nol ditandai dengan kata-kata ‘tidak ada pengaruh’, ‘tidak ada hubungan’, dan sejenisnya. Hipotesis alternatif adalah lawan dari hipotesis nol. Jika hipotesis nol tidak terbukti, maka hipotesis alternatif dapat diterima. Ambang batas paling umum yang digunakan peneliti untuk menolak hipotesis nol adalah 5 persen (0,05).
Dalam bab ini juga dibahas tipe-tipe error: Tipe I dan II
A type I error involves wrongly rejecting a true null hypothesis (false positive)
A type II error involves failing to reject a false null hypothesis (false negative)
Yang mana yang lebih baik, yang mana yang kebih buruk? Jawabannya tergantung kondisi. Dalam buku disebutkan 2 contoh sederhana, yakni dalam menyaring email spam, dan skrining kanker. Untuk spam filters, lebih baik untuk “menganggap” email-email non spam menjadi dpam agar user lebih aman; tapi sebaliknya, dalam skrining kanker, lebih baik menerima false positive (terkena kaker) untuk kemudian mengetahui bahwa sebenarnya kita sehat, daripada melewatkan diagnosis yang berpotensi fatal)

Ch. 10 Polling (p.169-184)
A poll (or survey) is an inference about the opinions of some population that is based on the views expressed by some sample drawn from that population.
1. Is this an accurate sample of the population whose opinions we are trying to measure? Selalu perhatikan peluang terjadinya selection bias
2. Have the questions been posed in a way that elicits accurate information on the topic of interest? Jadi sebuah pertanyaan jika diajukan dengan cara yang berbeda, maka akan menghasilkan jawaban yang berbeda pula dari responden. Jawaban orang sering kali berubah ketika informasi tambahan terkait pertanyaan tsb disertakan. Misalnya pertanyaan.
3. Are respondents telling the truth? Tidak selalu, bayak yang memanipulasi jawaban terutama untuk topik tertentu.
Ch. 11 Regression Analysis (p.185-211)
Metode yang digunakan untuk menentukan hubungan sebab-akibat antara satu variabel dengan variabel-variabel yang lain. Untuk menggunakan analisi regresi, kita harus memiliki satu variabel yang bersifat fixed atau tetap, sementara variabel Y bersifat random.
Jika variabel X nya lebih dari satu, Ordinary Least Squares (OLS) biasa digunakan untuk mengestimasi garis regresinya. “A residual is the vertical distance from the regression line minus the observations that lie directly on the line (for which the residual = 0). The larger the sum of residuals, the worse the fit of the line (the line of best fit)”
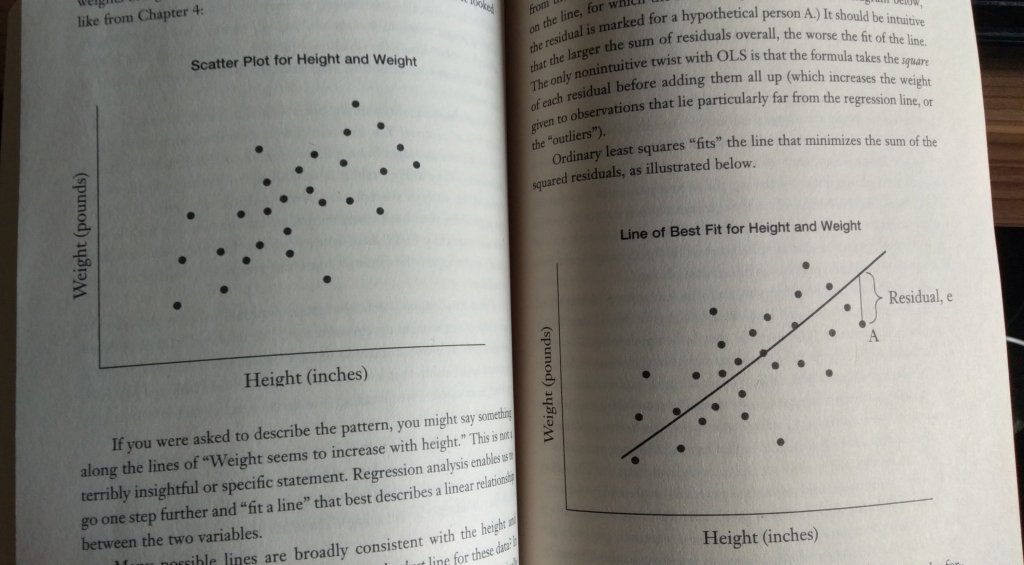
Bab ini cukup membuat kening saya berkerut, maklum belajar statistik sudah 7 tahun lalu. Jadi saya tulis yang paling mudah dicerna saja deh, hehe. Kalau penasaran isi lengkapnya sila purchase bukunya 😀
Ch. 12 Common Regression Mistakes (p.212-224)
Kesalahan yang sering terjadi saat menggunakan analisi regresi, diantaranya:
1. Using regression to analyze a non-linear relationship
Hanya untuk data yang linier
2. Correlation does not equal causation

3. Reverse causality
Pengeluaran tinggi untuk pendidikan = menyebabkan percepatan pertumbuhan ekonomi. Walaupun begitu, negara dengan ekonomi yang kuat juga semestinya menganggarkan lebih banyak dana untuk pendidikan itu sendiri. Kausalitas berjalan dua arah.
4. Omitted variable bias
Menghilangkan satu variabel dari beberapa variabel yang ada dapat mengubah hasil analisis karene dapat menyebabkan misleading regression.
5. Highly correlated explanatory variables (multicollinearity)
Multikolinearitas adalah sebuah kondisi yang menunjukkan adanya korelasi kuat antara dua variabel bebas atau lebih. Misalnya: kepuasan kerja (X1), gaya kepemimpinan (X2), dan motivasi (X3), dengan variabel dependennya yakni kinerja (Y). Keterikatan antara variabel-variabel tsb membuat analisa menjadi sulit jika ingin menentukan efek dari satu variabel tunggal.
6. Extrapolating beyond the data
“Results are valid only for a population that is similar to the sample on which the analysis has been done”
7. Data mining (too many variables)
“If you put enough junk variables in a regression equation, one of them is bound to meet the threshold for statistical significance just by chance”
Ch. 13 Program Evaluation (225-240)
“Will going to Harvard change your life?” pertanyaan tersebut serupa dengan “Does putting more police officers on the street deter crime? Keduanya tidak bisa dijawab begitu saja, harus dianalisa faktor-faktor apa yang ada di belakangnya. Los Angeles berbeda dengan Zurich, jadi berapa pun jumlah polisi yang berpatroli di jalanan belum tentu bisa menurunkan tingkat kriminalitas, berbeda tempat, berbeda demografi, berbeda jawaban, berbeda treatment yang harus dilakukan.
Untuk mencari treatment yang paling efektif, harus dilakukan berbagai uji coba. Berikut adalah beberapa pendekatan yang paling umum untuk mengisolasi efek treatment:
1. Randomized, controlled experiments
Ada kelompok kontrol dan ada kelompok yang mendapat treatment. Lingkungan di-set sedemikian rupa untuk meminimalisir gangguan faktor eksternal, dan spemberian treatment dilakukan kepada subjek secara acak (random).
2. Natural experiment
Adriana Lleras-Muney, seorang mahasiswa pascasarjana di Universitas Columbia mempelajari hubungan antara sekolah/pendidikan dan harapan hidup di kemudian hari. Dia melakukan ini dengan membandingkan negara bagian Amerika yang mengubah UU pendidikan vs yang tidak mengubah UU pendidikan, dalam hal ini lama sekolah minimum (semacam wajib belajar di Indonesia)
3. Non-equivalent control
Ada kelompok kontrol dan treament, tapi subjek-subjeknya tidak dirandomisasi sehingga berpotensi menimbulkan bias.
4. Difference in differences
Pemberian intervensi terkadang memberi dampak negatif bagi variabel dependen. Misalnya pemberian training kerja untuk masyarakat Regional A, apakah berdampak pada tingkat pengangguran di Regional A tsb atau tidak. Grafik di bawah menunjukkan perbedaan antara before-after tingkat pengangguran Regional A vs Regional B. Jika tidak diberi intervensi training kerja, maka kita akan dengan mudahnya mengatakan bahwa tingkat pengangguran di Regional A meningkat. Tetapi, jika kita membandingkannya dengan Regional B yang warganya tidak diberi training, maka penambahan jumlah pengangguran di Regional A tidak begitu berarti. Dalam hal ini bahkan dapat dikatakan jika training bisa menurunkan tingkat pengangguran (yang seharusnya terjadi -pen)

Wallahu a’lam bishawab
Naked Statistics Stripping the Dread from the Data, dipublikasikan oleh Norton
Jumlah halaman: 282 hlm (13 bab + notes dan index)
Link untuk membeli buku: amazon, bookmatch.nl
Eindhoven, 12 April 2022 16:00 CEST (Ramadan d-11)

Suka 🥰
LikeLiked by 1 person
Makasiih biidaa, mudah2an bermanfaat 😊
LikeLiked by 1 person